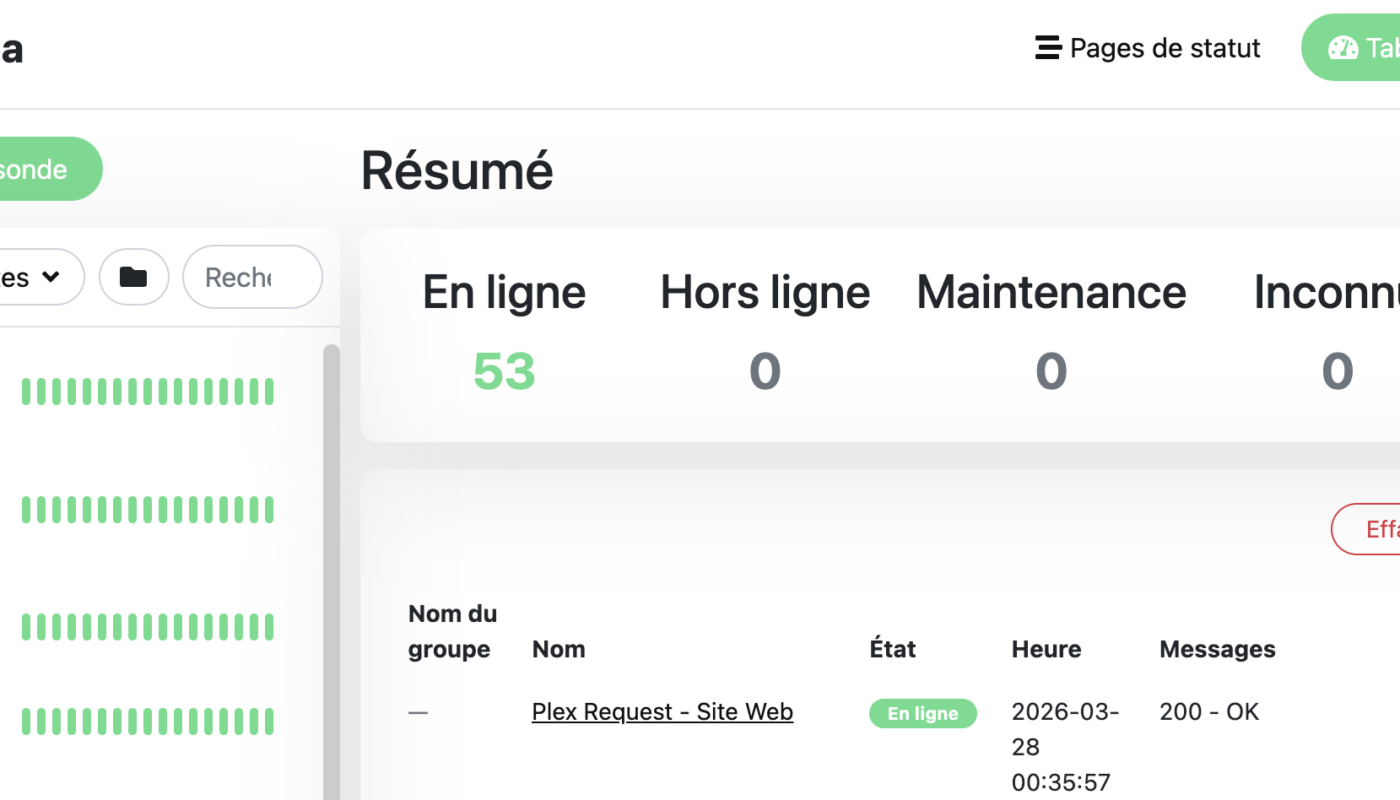
En plein après-midi, un de mes services est tombé. Je l’ai su deux minutes plus tard. C’est ça, Uptime Kuma : pas de service KO sans qu’on le remarque. Une alerte Telegram sur le téléphone, et tu sais exactement ce qui ne répond plus.
C’est là qu’Uptime Kuma est entré dans mon setup. Et depuis, je sais exactement ce qui tourne — et ce qui ne tourne pas.
Pourquoi Uptime Kuma
Il existe pas mal de solutions de monitoring : Zabbix, Nagios, Prometheus + Grafana, Hetrix… Pour un homelab personnel, la plupart sont overkill. Zabbix demande une demi-journée de configuration. Grafana + Prometheus, c’est puissant mais complexe à maintenir.
Uptime Kuma coche toutes les cases :
- Installation en une commande (Docker ou LXC Proxmox)
- Interface web propre et moderne, refaite en 2.0
- Notifications : Telegram, Discord, email, webhook, push et plus de 90 canaux
- Gratuit et open source (créé par Louis Lam, le même dev que Dockge)
- Léger : un seul container ou LXC, ~80 Mo de RAM
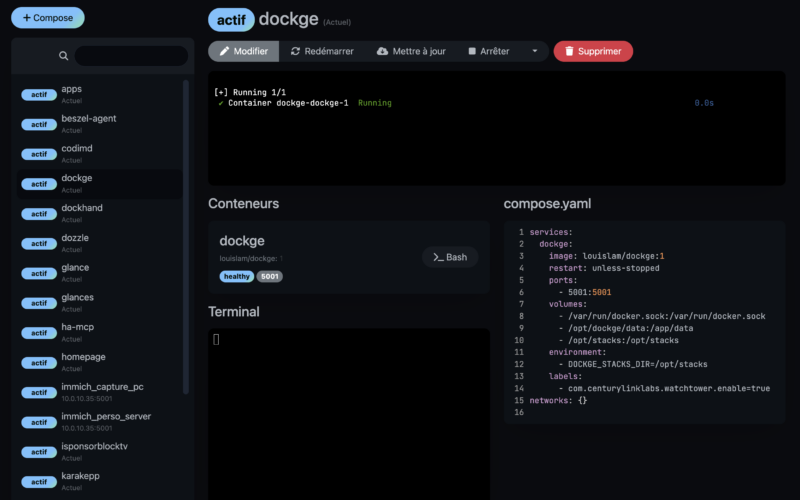
Installation Docker via Dockge
Si tu utilises Docker, la stack est minimale. Comme tous mes containers, je gère Uptime Kuma via Dockge :
services:
uptime-kuma:
image: louislam/uptime-kuma:2
container_name: uptime-kuma
restart: unless-stopped
ports:
- "3001:3001"
volumes:
- ./data:/app/data
# Dans Dockge : Create Stack > coller le compose > Deploy
docker compose up -d
Accès à http://<IP>:3001. Crée ton compte admin et c’est parti.
Mon setup actuel : LXC Proxmox en haute disponibilité
Avant, j’avais trois instances Uptime Kuma sur trois nœuds Proxmox — chacune pingait les deux autres. Ça fonctionnait, mais c’était lourd à maintenir : trois configurations à synchroniser, trois listes de monitors à garder à jour.
Aujourd’hui, j’ai simplifié : un seul LXC Uptime Kuma, disponible en haute disponibilité sur mon cluster Proxmox. Si le nœud qui l’héberge tombe, Proxmox HA migre automatiquement le LXC sur un autre nœud. Plus besoin de trois instances.
L’installation s’est faite via le script communautaire Proxmox VE :
bash -c "$(curl -fsSL https://raw.githubusercontent.com/community-scripts/ProxmoxVE/main/ct/uptimekuma.sh)"
Le script crée un LXC Debian avec Uptime Kuma préinstallé (1 core, 1 Go RAM, 4 Go stockage — largement suffisant pour 50+ monitors). Le LXC est ensuite sauvegardé automatiquement via Proxmox Backup Server, comme tous mes autres LXC critiques.
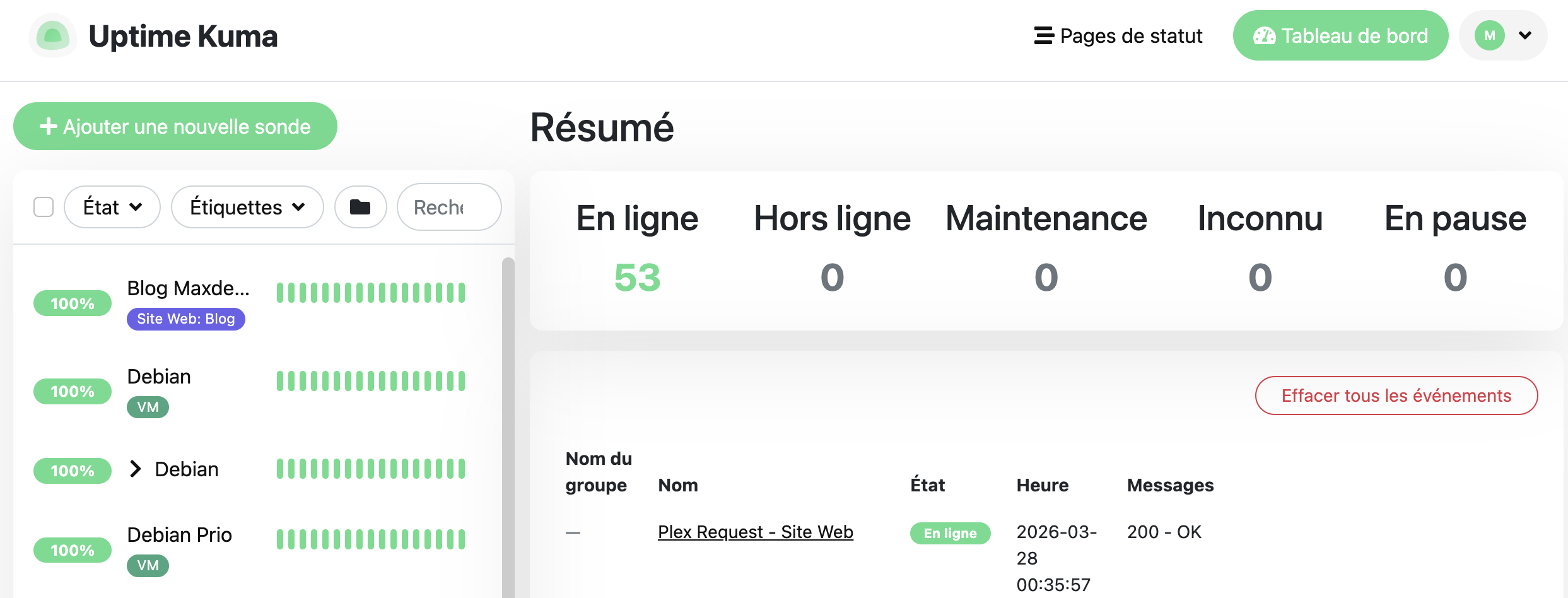
La migration vers Uptime Kuma 2.x
La version 2.0 est sortie en octobre 2025 avec pas mal de nouveautés : support MariaDB, images Docker rootless, interface modernisée, et de nouvelles intégrations (Nextcloud Talk, Brevo, monitoring d’expiration de domaines en 2.1).
J’ai essayé de migrer depuis la 1.x — sans succès. La migration de la base SQLite ne s’est pas bien passée dans mon cas. Plutôt que de me battre avec, je suis reparti de zéro. Et c’était finalement une bonne décision : j’en ai profité pour :
- Créer des tags propres par catégorie (Infrastructure, Réseau, Media, Docker, Backup…)
- Organiser les monitors en groupes logiques plutôt que la liste à plat que j’avais avant
- Revoir les intervalles de check en fonction de la criticité de chaque service
Recréer 50 monitors prend une petite heure, mais le résultat est bien plus lisible qu’avant.
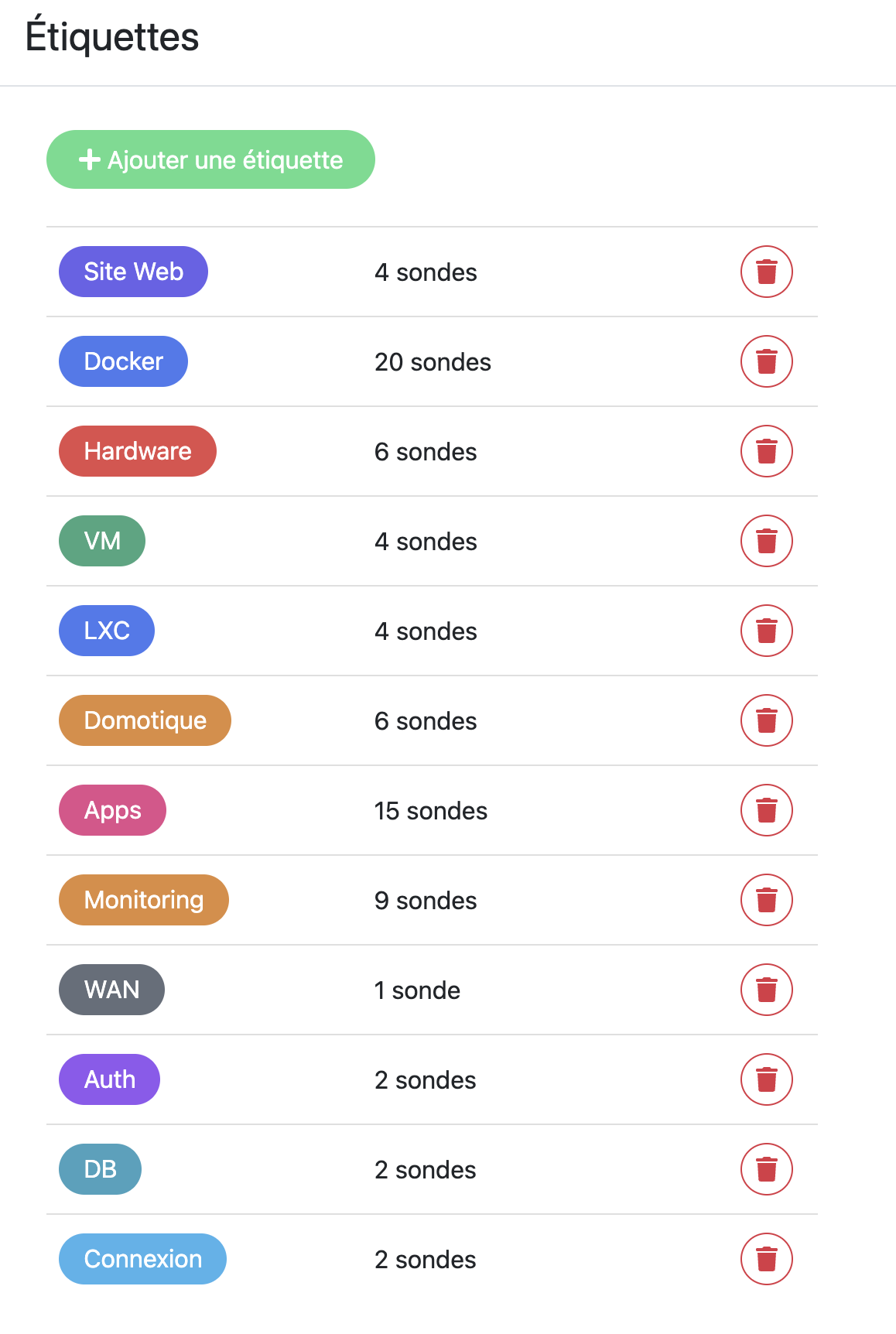
Ce que je monitore — 50+ monitors organisés par tags
Le regroupement par tags et groupes est essentiel quand tu dépasses la vingtaine de services — sinon c’est illisible.
Infrastructure critique (check toutes les 60s)
- Home Assistant : HTTP check sur
http://<IP>:8123— si HA tombe, toute la domotique s’arrête - Proxmox nœud 1, 2 et 3 : HTTP check sur l’interface web + ping
- NAS UNAS Pro : HTTP check + ping
- AdGuard Home : HTTP check — si le DNS tombe, plus rien ne résout sur le réseau
Réseau et sécurité (check toutes les 60s)
- Dream Machine SE : HTTP check + ping + check connexion fibre et connexion 4G LTE de secours
- Nginx Proxy Manager : HTTP check sur le dashboard
- Certificats SSL : checks expiration sur chaque domaine exposé
Services media (check toutes les 120s)
- Plex : HTTP check sur le port 32400
- Sonarr / Radarr / Prowlarr : HTTP check
- Overseerr : HTTP check
- Tautulli : HTTP check
Services Docker divers (check toutes les 120s)
- Glance : HTTP check
- Dockge : HTTP check sur les 3 agents
- TeslaMate, Immich, FreshRSS, Wallos… : HTTP check
J’ai aussi configuré les checks de certificats SSL sur tous mes services exposés en HTTPS. Uptime Kuma te prévient 14 jours avant l’expiration. Plus jamais de certificat expiré un dimanche matin.
Pour les heartbeat monitors (scripts cron, backups automatiques), c’est sur ma todolist — je n’ai pas encore mis ça en place, mais c’est prévu. J’en parle plus bas dans les tips.
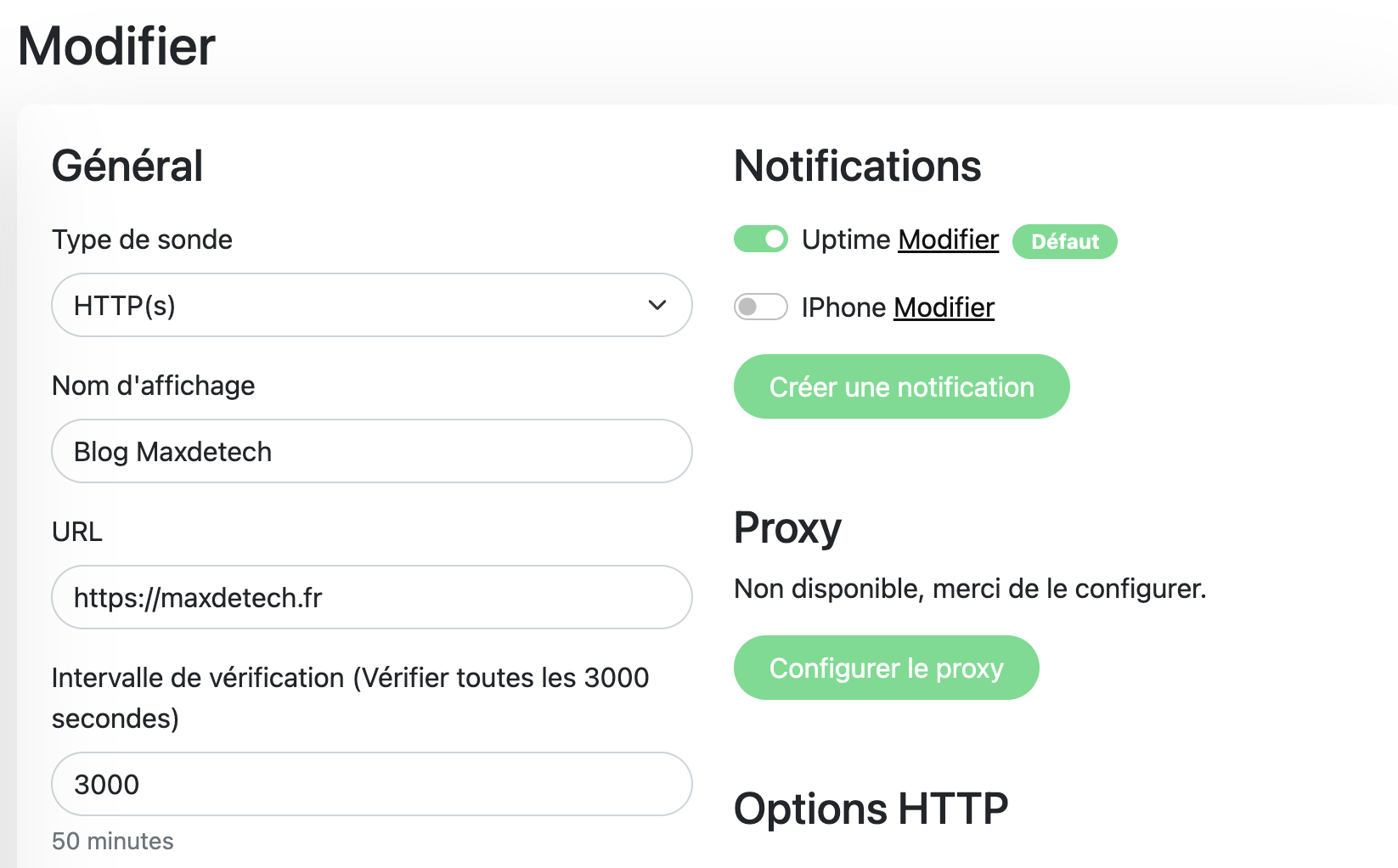
Les notifications Telegram sur iOS
Un monitoring sans alertes, ça ne sert à rien. Dans mon cas, j’utilise Telegram avec les notifications push iOS. Un service tombe, je le sais en moins d’une minute — même en 4G loin de chez moi, sans VPN, sans être sur le réseau local.
La configuration dans Uptime Kuma : Settings > Notifications > Add Notification > Telegram. Tu crées un bot via BotFather, tu récupères le token et ton chat ID, et c’est réglé.
Uptime Kuma supporte plus de 90 canaux de notifications — Discord, email, webhook, Gotify, Slack, Ntfy… Toi tu choisis ce qui te convient. Moi, Telegram suffit largement : fiable, instantané, et ça fonctionne partout.

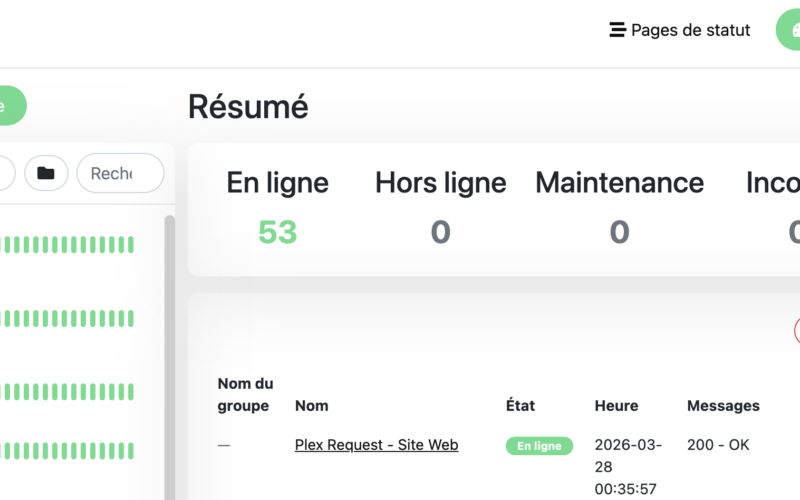
Les pages de statut publiques
Un bonus qu’on sous-estime : Uptime Kuma permet de créer des pages de statut publiques. Si tu héberges des services pour ta famille ou tes amis — Plex, Immich, Nextcloud — tu peux leur partager une URL qui montre en temps réel ce qui fonctionne ou non.
Plus besoin de répondre à « ça marche pas Plex ? » — ils peuvent vérifier eux-mêmes avant même de te contacter.
Les limites d’Uptime Kuma
Uptime Kuma surveille la disponibilité, pas la performance. Il vérifie que tes services répondent, point. Pour les métriques CPU, RAM et IOPS, c’est Beszel ou Glance qui prennent le relais chez moi.
L’autre risque classique : si le serveur qui héberge Uptime Kuma tombe, plus de monitoring. Dans mon cas, le LXC tourne en haute disponibilité Proxmox — il migre automatiquement sur un autre nœud. Problème résolu.
Configure des heartbeat monitors pour chaque script cron important. Le principe : le script lui-même fait un appel HTTP vers une URL Uptime Kuma après s’être exécuté avec succès. Si le heartbeat n’arrive pas à l’heure prévue, tu reçois une alerte.
C’est grâce à ça qu’on peut détecter si un backup est KO — un script qui crashe silencieusement ne produit pas d’erreur visible, mais le heartbeat manquant, lui, déclenche une alerte. C’est sur ma todolist de le mettre en place pour mes backups Proxmox, et je mettrai l’article à jour quand ce sera fait.
# En fin de script de backup, ajouter :
curl -s "https://uptime-kuma.domain.com/api/push/<TOKEN>?status=up&msg=OK"Dans Uptime Kuma : New Monitor > Type « Push » > définir l’intervalle attendu. Si le push n’arrive pas dans le délai configuré → alerte Telegram. Simple, efficace, et ça te force à vérifier que tes scripts tournent vraiment.
Conclusion
15 minutes d’installation, une heure pour configurer tes monitors, et tu as un système de surveillance qui tourne 24h/24. Mon conseil : commence par tes 10 services les plus critiques, organise-les avec des tags et des groupes dès le départ, et active la page de statut publique.
Étape suivante : Beszel pour les métriques de performance, Nginx Proxy Manager pour donner des URLs propres à surveiller, et Dockge pour gérer tes containers. Tout est dans mon setup homelab 2026.